Distributed data management architecture for Calvera
Architecture
At ORNL we have multiple sources of data stored in different isolated locations. One can call this storage a datalake (although data islands would probably be more appropriate). To be able to work with this data, we use a distributed data management approach based on Rucio. With this approach, we configure multiple Rucio Storage Elements (RSE), one for each storage. Depending on an RSE and compute resource location, relative to this RSE, we select the most efficient file transfer protocol to use. Let's consider various data sources, required functionality and protocol choice.
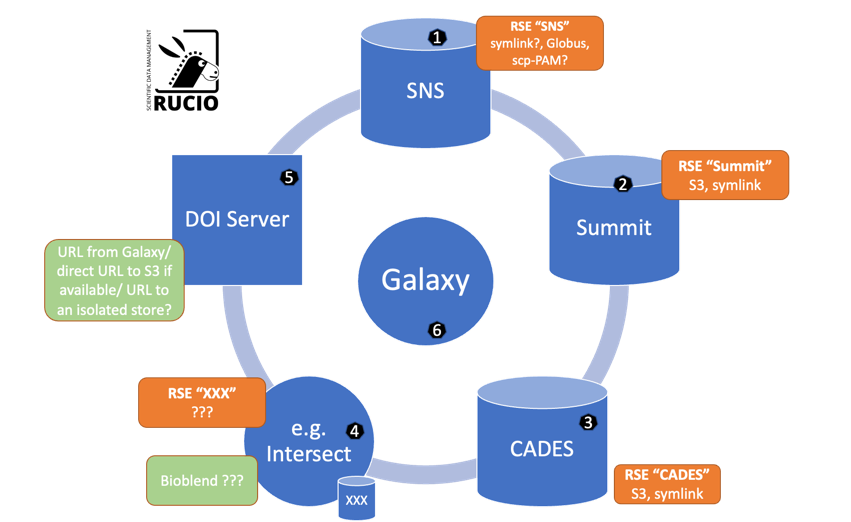
(1) SNS Analysis cluster
This is a main source of Neutron experimental data.
Functionality
- Ingest data to the datalake: no copy, we just add metadata to Rucio RSE about this data
- Export data from the datalake: copy, via a tool.
- Use this storage as Galaxy storage: later,we might reserve part of SNS storage and use it as a part of the datalake.
Supported protocols
- symlink: when /SNS and /HFIR are mounted on compute resource. Rucio will just create a symlink to a file
- some other protocol for remote data access. S3/Globus/scp-pam?
(2) Summit
Functionality
- Get data from the datalake: no copy for the case when data is already on Summit, copy data when it is in the other part of the lake.
- Ingest data to the datalake: no copy, we just add metadata to Rucio RSE about this data, tha data stays on Summit.
Supported protocols
- symlink: when data is on GPFS. Rucio will just create a symlink to a file
- S3 for remote data access (need to deploy MinIO and open a port)
(3) CADES
Functionality
- Get data from the datalake: no copy for the case when data is already on CADES (SNS/HFIR data is mounted there as well), copy data when it is in the other part of the lake (currently only Summit).
- Ingest data to the datalake: copy to the CEPH storage
Supported protocols
- symlink: when data is on CEPH or /SNS,/HFIR. Rucio will just create a symlink to a file
- S3 for remote data access (need to deploy S3 gateway for CEPH)
(4) Connection to other services
We still need to figure out what would be the use case. A universal solution (probably not the most efficient) is to use Bioblend to work with Galaxy data. If another system is using some storage solution, one can probably also configure an RSE for it.
Functionality
- Get data from the datalake: download data using bioblend, use RSE
- Ingest data to the datalake: upload data using bioblend, use RSE
Supported protocols
???
(5) Generating DOI
If a DOI service need to provide access to Galaxy data, one could use dataset, data collection and history URLs for that. But this will only work internally. A better solution would probably be a dedicated public data store and a Galaxy tool to create a DOI and push data to that store.
(6) Galaxy (web/api frontend)
since Galaxy services run on CADES, data management would be the same.
Risk assessment
| Risk | Probability | Severness | Mitigation | Time to assess | Time to mitigate |
|---|---|---|---|---|---|
| Rucio is a wrong solution | Low | High | Switch to iRods | 2 months | 2 months |
| iRods is a wrong solution | Low | High | Look for something else, worst case – keep using Galaxy and unmanaged data | 2 months | |
| ORNL comes with system-wide data management solution | Low | Medium | Write an object store that uses this system | 2 months | |
| We get no firewall opened from outside (CADES) to Marble | Medium | Medium | Invert data flow, push data from Summit instead of pulling from outside | we should start asking | 2 months |